Distrees (Distributed HTML Trees) are like B-trees, except the nodes are stored in HTML. Duplicate nodes and overlapping nodes are allowed. Distrees can be searched by hand, they are just HTML files with ordered lists of links. Distrees fills two needs:
Search engines have been having a hard time recently. Go folded because it was losing money fast. DejaNews folded too, same reason, but its data was saved in the nick of time by Google. Yahoo was shut down by hackers. MSN was shut down by its own poorly configured servers. Perhaps the scariest of all, Napster has been hamstrung by lawsuits and the sympathetic US courts. Gnutella tried to avoid the lawyers and bad business plans by having no central server, but it also has no index, which is self-defeating (it stops working when there are more than a couple thousand users).
There is a need for a search engine that is not vulnerable to hackers, lawyers, and bad business plans. It needs an index, but the index must be distributed, with no central servers. This page defines Distrees, which fill that need.
As it happens, a distree can fill another need as well, a totally noncontroversial one. Hosted sites can index themselves with a distree without any serverside processes or scripts.
A distree node is a fragment of an HTML file. (The filename does not matter, but it must stay fixed once other nodes start linking to it.) There should be one node per file (except when that node has recently shrunk). The fragment is surrounded by the tags <distree> .. </distree>. Certain tags within the fragment have standard meanings inside a distree node. Extra tags, and text outside of any tags, is allowed.
The fragment should contain these fields:
Each child item should contain these fields:
Nodes do not have to be stored in this HTML format. Other formats are more space efficient and easier to search. However, in order to be distree nodes, this format must be supplied upon request. This allows independent software to use the nodes for searches and maintenance.
An HTML file may contain only one node. Nodes must be higher than all their children. Ranges should be shrunk once a file reaches 10 Kbytes. A node's subtree must be at least 16x the size of its largest child's subtree, except when that node is the root.
Nodes are created at a certain height. Their range may shrink or grow, but they do not change height. If the root node needs to shrink its range, a new root must be created as its parent.
When a node shrinks its range, a new node must be created holding the orphaned children. A copy of the new node should be placed temporarily in the same file as the official node, below the official node.
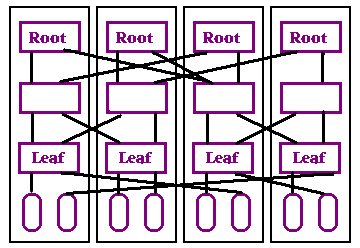
|
| A Distributed HTML Tree |
|---|
Distributed distrees have additional rules.
If a machine stores an indexed entry, it is encouraged to store a leaf holding the indexing key. Any machine storing a leaf must store the complete path from the root to that leaf. These single-machine paths must never be broken. Any shrinkage of ranges must maintain the paths.
When a machine first adds leaves, it must submit those leaves to at least one other machine with leaves indexing the same range. This step makes the preexisting distributed index aware of the new leaves, branches, and indexed entries.
Children may have overlapping ranges. In fact, nodes are encouraged to have 3 to 4 children covering each point in their range, preferably all on different machines. The purpose of this is to fully connect the distributed tree and keep it connected even if many machines go down.
Machines are encouraged to regularly check links and update the ranges, dates checked, and status of their children.
Machines are also encouraged to look at neighbors and update their children based on them. A node's neighbor is at the same height with an overlapping range, but on a different machine. A node can add children from its neighbors that it doesn't know about. Leaves should always index new entries, and should split when they get too big. Higher levels do not need a complete list of nodes in their range at lower levels, they just need to cover their range adequately. If there are two children on remote machines, where the second child has a a range that is a subset of the first and larger subtree than the first, the second child is preferred. A node that disobeys rules is not an acceptable child, but that node's children may make acceptable children for the current node or the current node's children.
When a node shrinks its range, a new node containing children in the old range should be created in the same file. After a suitable aging-out period, the extra node can be deleted. When a file with an extra node of orphaned children is found as a neighbor, linking to those orphaned children is high priority. Adding submitted entries and merging with submitted branches is also high priority.
Depth: The tree is limited in height because every node must have a subtree at least 16x the size of each of its children's subtrees. A tree with one million entries would be of height 5 or less. A distree with one trillion entries would be height 10 or less.
Storage: A machine storing just one leaf must store just one node at every height from leaf to root. For a tree with a trillion entries, assuming all nodes obey the 16x and 10Kbytes rules, that machine would need to store at most 10 nodes of 10Kbytes each for a total of 100K. All modern websites allow at least 1000Kbytes of storage. Any website can take part in a distributed tree, no matter how large the tree, no matter how small the site. On the other hand, if a site stores L leaves in a trillion-node distree, the storage required would be roughly L*100Kbytes. On the other hand (where did all these hands come from?), storing L consecutive leaves would be just (90 + L*10)Kbytes.
Fault tolerance: There are duplicates of each node, with about as many duplicates as there are entries for leaves, and the number of duplicates grows exponentially from there with the height of the node. The only thing not duplicated is the entries themselves. Access to the index root is guaranteed to every machine with leaf nodes, since having a leaf node requires also storing a copy of the index root. The duplicates will not be exact duplicates, in fact they will be nowhere close.
Usability: If you search from an arbitrary root for a specific indexed item, will you find it? Not necessarily. There are duplicate leaves, and it is likely that not all leaves cover all indexed items in their range. It depends how much neighbor-synching the individual leaves do. It also isn't easy to find all the leaves covering a given range. If you attempt to walk all paths from a root to a given key in a tree with N entries, there are roughly sqrt(N) distinct branches halfway down the tree that those paths pass through. Most indexed entries in a given range can be found by looking at just log(N) nodes, but finding all indexed entries in a given range is very expensive to impossible.
Bandwidth:If a root is at height log(N), a search will usually require visiting log(N) machines. That's worse than 1 for central servers, but it's far better than N for brute-force search. This scheme allows some machine to store leaves covering the entire range, and thus the entire tree. If that machine prefers searching nodes that it stores, then starting at the root of that machine would give you the 1 machine access of today's central server search engines. Today's central server search engines could become a distree as well by generating node files upon request. (They would be impolite distrees because they wouldn't index any nodes outside of their own machine.)
Censorship: Can leaf owners edit their leaves? alter comments? keys? link? censor certain content? Sure. They can even delete their leaves on a whim. Same with branch owners. It's not a polite thing to do, but nothing prevents it. Note though that all nodes, including leaves, are duplicated. Semiofficial lists of obnoxious owners seems like a likely development.
Spam: Anyone can submit any entry they want. Note, though, that the leaf owners have the power to choose which entries they actually store.
Distrees are like B-trees, but they are implemented as ordered lists in HTML files. They can be traversed by hand. It is harder to attack a distributed distree than to attack the indexed entries because its roots and branches and even leaves are massively duplicated.
What remains to be done is, well, everything. No code has been written. No indexes have even been built by hand. Between family and job, it will take me a long time to get this implemented. If anyone wants to contribute to the cause of saving search engines, talk to me!